This post briefly summarizes a NeurIPS-20 paper, Probabilistic Fair Clustering, which I coauthored with Brian Brubach, Leonidas Tsepenekas, and John P. Dickerson.
Clustering is possibly the most fundamental problem of unsupervised learning. Like many other paradigms of machine learning, there has been a focus on fair variants of clustering. Perhaps the definition which has received the most attention is the group fairness definition of [1]. The notion is based on disparate impact and simply states that each cluster should contain points belonging to the different demographic groups with “appropriate” proportions. A natural interpretation of appropriate would imply that each demographic group appears in close to population-level proportions in each cluster. More specifically, if we were to endow each point with a color 


Here, 


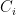

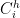

If one were to use clustering for market segmentation and targeted advertisement, then the above definition of fair clustering would roughly ensure that each demographic group receives the same exposure to every type of ad. Similarly if we were to cluster news articles and let the source of each article indicate its membership then we could ensure that each cluster has a good mixture of news from different sources [2].
Significant progress has been made in this notion of fair clustering starting from only considering the two color case and under-representation bounds, to the multi-color case with both under- and over-representation bounds [3.4.5]. Scalable methods for larger datasets have also been proposed [6, 7].
Clearly, like the majority of the methods in group-fair supervised learning, it is assumed that the group membership of each point in the dataset is known. This setting conflicts with a common situation in practice where group memberships are either imperfectly known or completely unknown [8,9,10,11,12]. We take the first step in generalizing fair clustering to this setting; specifically, we assume that while we do not know the exact group membership of each point, we instead have a probability distribution over the group memberships. A natural generalization of the previous optimization problem would be the following:
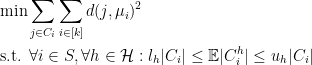
Where the proportionality constraints were simply changed to hold in expectation instead of deterministically. Clearly, this constraint reduces to the original constraint when the group memberships are completely known. Figure 2 helps visualize how the input to probabilistic fair clustering looks like and the output we expect.

Despite the innocuous modification to the constraint, the problem becomes significantly more difficult. In our paper, we consider the center-based clustering objectives of
- Two-Color Case: We see that even the two color case is not easy to handle. The key difficulty lies in the rounding method. However, we give a rounding method that maintains the fairness constraint with a worst-case additive violation of 1 matching the deterministic fair clustering case.
- Multi-Color Case with Large Enough Clusters: At a high level, if the clusters have a sufficiently large size then through a Chernoff bound we can show that independent sampling would result in a deterministic fair clustering instance which we could solve using deterministic fair clustering algorithms. This essentially forms a reduction from the probabilistic to the deterministic instance.
While our solutions perform well empirically, we are left with a collection of problems. For example, guaranteeing that the color proportions are maintained in expectation is not the best constraint one should hope for, since when the colors are realized a cluster could entirely consist of one color. A more preferable constraint would instead bound the probability of obtaining an “unfair” clustering. Moreover, a setting that assumes access to the probability distribution for a given point over all colors could still be assuming too much. A more reasonable setting could instead take a robust-optimization-based approach, where we have the distribution of each point but allow the distribution of each point to belong to an uncertainty set. This effectively allows our probabilistic knowledge to be imperfect as well—as could be the case if, for example, a machine learning model were predicting group membership with a systematic bias against a particular subset of colors. Lastly, being able to handle the multi-color case in an assumption-free manner would also be interesting.
References:
- Flavio Chierichetti, Ravi Kumar, Silvio Lattanzi, and Sergei Vassilvitskii. Fair clustering through fairlets. In Advances in Neural Information Processing Systems, 2017.
- Sara Ahmadian, Alessandro Epasto, Ravi Kumar, and Mohammad Mahdian. Clustering without over-representation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2019.
- Melanie Schmidt, Chris Schwiegelshohn, and Christian Sohler. Fair coresets and streaming algorithms for fair k-means. In the International Workshop on Approximation and Online Algorithms, 2019.
- Ioana O. Bercea, Martin Groß, Samir Khuller, Aounon Kumar, Clemens Rösner, Daniel R. Schmidt, Melanie Schmidt. On the cost of essentially fair clusterings, In the International Conference on Approximation Algorithms for Combinatorial Optimization Problems 2019.
- Suman Bera, Deeparnab Chakrabarty, Nicolas Flores, and Maryam Negahbani. Fair algorithms for clustering. In Advances in Neural Information Processing Systems, 2019.
- Arturs Backurs, Piotr Indyk, Krzysztof Onak, Baruch Schieber, Ali Vakilian, and Tal Wagner. Scalable fair clustering. In the International Conference on Machine Learning, 2019.
- Lingxiao Huang, Shaofeng Jiang, and Nisheeth Vishnoi. Coresets for clustering with fairness constraints. In Advances in Neural Information Processing Systems, 2019.
- Pranjal Awasthi, Matth¨aus Kleindessner, and Jamie Morgenstern. Equalized odds postprocessing under imperfect group information. In the International Conference on Artificial Intelligence and Statistics, 2020.
- Preethi Lahoti, Alex Beutel, Jilin Chen, Kang Lee, Flavien Prost, NithumThain, Xuezhi Wang, and Ed Chi. Fairness without demographics through adversarially reweighted learning. In Advances in Neural InformationProcessing Systems, 2020.
- David Pujol, Ryan McKenna, Satya Kuppam, Michael Hay, AshwinMachanavajjhala, and Gerome Miklau. Fair decision making using privacy-protected data. In Proceedings of the Conference on Fairness, Accountability, and Transparency, 2020.
- Hussein Mozannar, Mesrob Ohannessian, and Nathan Srebro. Fair learning with private demographic data. In the International Conference on Machine Learning, 2020.
- Nathan Kallus, Xiaojie Mao, and Angela Zhou. Assessing algorithmic fairness with unobserved protected class using data combination. Management Science, 2021.